Welcome to our in-depth guide on prompt engineering, a pivotal aspect of creating exceptional applications powered by Large Language Models (LLMs). In this article, we’ll delve into the art and science of prompt engineering, providing insights and strategies for optimizing AI interactions. We will also highlight GitHub Copilot, an example of an LLM-based application that has revolutionized code completion. Whether you’re a seasoned developer or just starting with AI, this guide will equip you with valuable knowledge to harness the full potential of LLMs in your projects.
The Rise of Generative AI
In the fast-paced world of technology, we’ve witnessed remarkable advancements. Over a decade ago, Marc Andreessen famously stated that “Software is eating the world.” Today, we’re experiencing the rise of a new technological force – generative artificial intelligence (AI). This innovative AI comprises a special category of models known as Large Language Models (LLMs), born from a decade of groundbreaking research. These LLMs possess the capability to outperform humans in specific tasks. Remarkably, you don’t need a Ph.D. in machine learning to harness the power of LLMs. Developers are already building software applications using LLMs through basic HTTP requests and natural language prompts.
Understanding Large Language Models
At the core of LLMs lies the ability to predict the next sequence of words, often referred to as “tokens.” Imagine the predictive text feature on your smartphone, where you’re presented with suggestions for the next word as you type. LLMs work similarly, but instead of a single word, they predict entire sequences of tokens. This predictive process continues until it reaches a predefined token limit or encounters a signal to stop, effectively completing a document.
However, LLMs are not your average predictive text algorithm. While your phone’s model may base predictions on the last two words entered, LLMs are trained on an extensive dataset, drawing from the entirety of publicly available documents. This extensive training empowers LLMs with a remarkable degree of common sense and context-awareness. For instance, they can understand that a glass ball on a table may roll off and shatter, showcasing their ability to generate responses grounded in real-world understanding.
Yet, it’s important to note that LLMs are not infallible. They may occasionally produce information that is incorrect or generate outputs beyond their initial training. These instances are known as “hallucinations” or “fabulations.” Moreover, LLMs can adapt and perform tasks they weren’t explicitly trained for, expanding their capabilities beyond their original scope.
Building Applications with LLMs
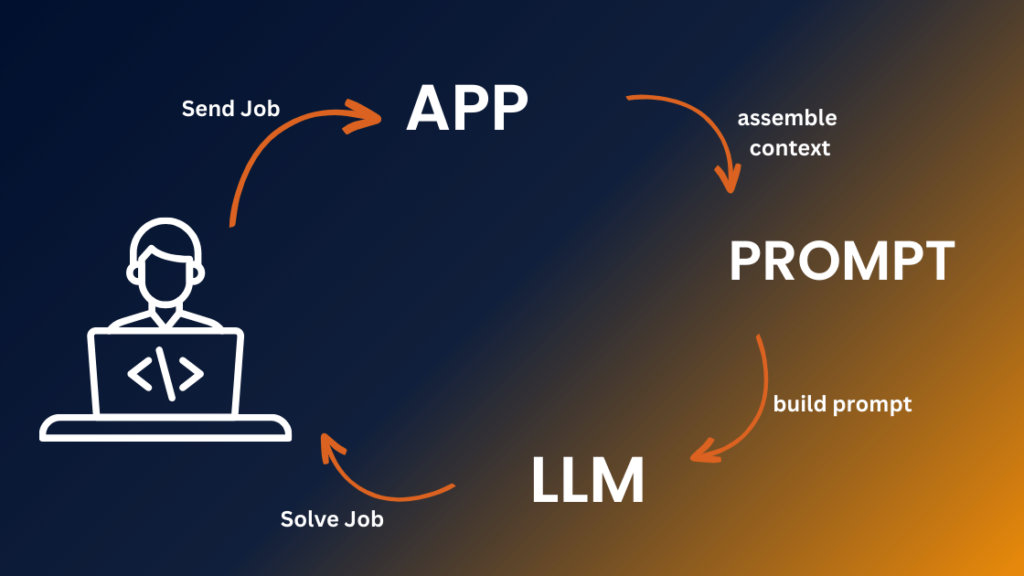
While the concept of document completion is akin to the predictive text feature on your phone, LLMs are capable of much more. They serve as the foundation for a diverse range of applications, from conversational search and writing assistants to automated IT support and code completion tools like GitHub Copilot. But how do these applications emerge from what essentially started as a document completion tool? The key lies in mapping between two domains: the user domain and the document domain.
Consider a scenario where a user, let’s call him Dave, encounters an issue with his Wi-Fi on the day of a crucial World Cup watch party. He reaches out to his internet provider, initiating a conversation with an automated assistant. If we were to implement this assistant as an LLM application, we’d need to convert Dave’s speech into text and provide context to bridge the user and document domains. This context includes defining the conversation as an “ISP IT Support Transcript,” setting the stage for the AI to understand its role as an IT support expert.
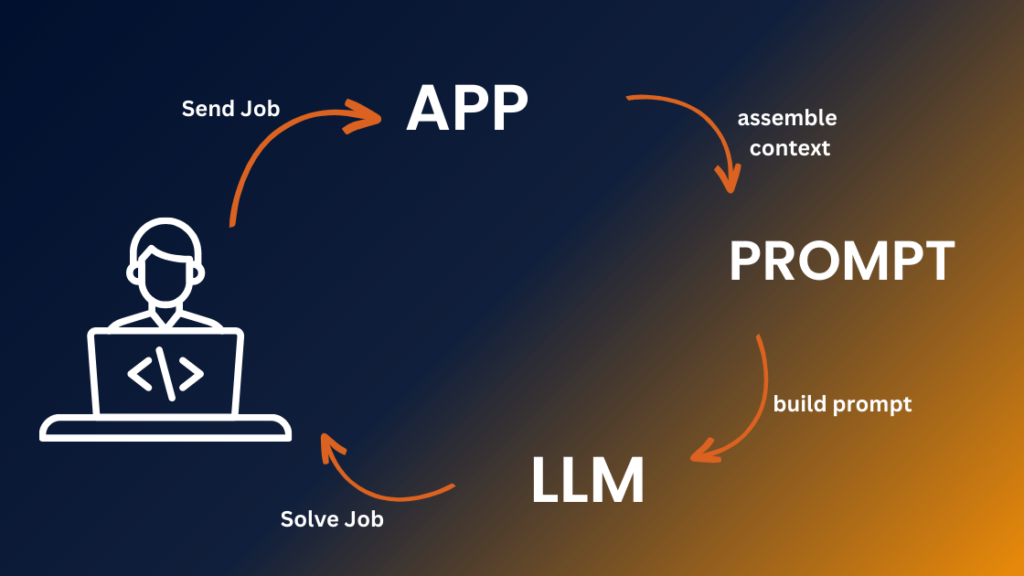
The beauty of prompt engineering lies in crafting a prompt with sufficient context for the AI to generate the best possible response. In this case, it means offering Dave helpful advice to resolve his Wi-Fi issue. The LLM, with this context, can generate a response that aligns with an IT expert’s guidance.
The Art and Science of Prompt Engineering
Prompt engineering is the cornerstone of effective AI interactions, and GitHub has refined its techniques over years of working with GitHub Copilot. Let’s explore the key aspects of prompt engineering and how they apply to GitHub Copilot.
Gathering Context
In the world of AI, context is king. GitHub Copilot operates within an Integrated Development Environment (IDE) like Visual Studio Code, utilizing the available context to provide rapid suggestions. Every millisecond matters in this interactive environment, so the AI must quickly gather relevant information.
For instance, it can determine the user’s coding language from the IDE, allowing it to tailor its suggestions accurately. Furthermore, it can leverage the content of open files within the IDE, providing valuable context for coding tasks. By understanding what other files are open, the AI can offer more informed suggestions.
Snippeting
To maintain accuracy and relevance, the AI must be selective in the information it uses. Source code can be extensive, and an LLM’s context window has limits. Therefore, irrelevant information should be omitted. Additionally, source code files can be lengthy, potentially exceeding the context window. In such cases, the AI should extract relevant portions or snippets to maintain efficiency.
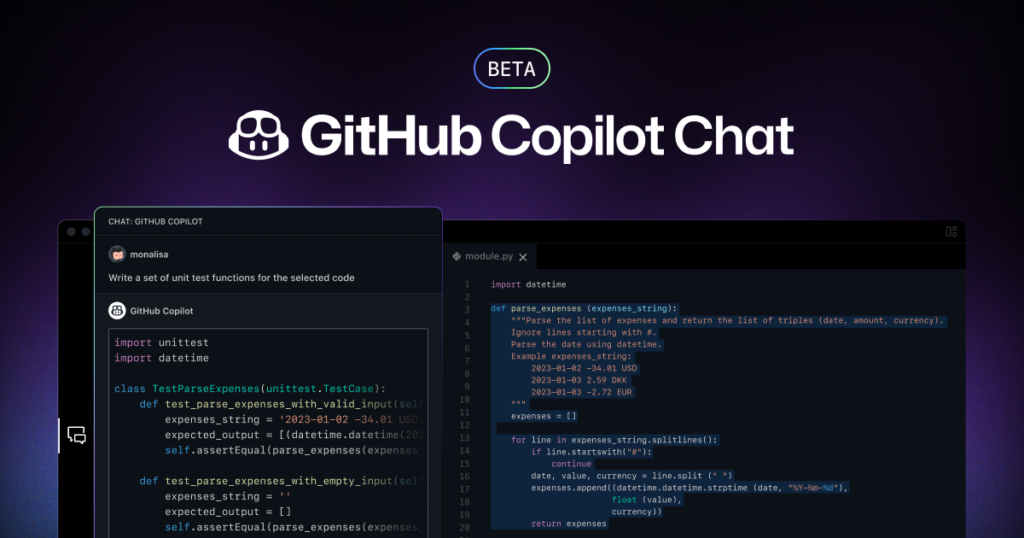
GitHub Copilot: A Case Study
GitHub Copilot exemplifies the power of prompt engineering in the context of code completion. It utilizes LLMs trained to complete code files on GitHub. While document completion is the fundamental task, GitHub Copilot tackles the unique challenges of code completion.
For instance, it recognizes that most files committed to a code repository are unfinished, often containing incomplete or uncompiled code. GitHub Copilot can predict code completions intelligently by considering not only the immediate context but also metadata, imports, and the broader repository context. It understands that software development is a complex, interconnected process, and the more context it can harness, the better its code completions become.
Conclusion
Prompt engineering is the linchpin of effective AI interactions, enabling LLMs to excel in various applications, including code completion. By understanding the nuances of gathering context and selecting relevant snippets, developers can harness the full potential of LLMs like GitHub Copilot.
As technology continues to advance, prompt engineering will remain a vital discipline, empowering AI-driven applications to enhance productivity and creativity in numerous domains. Whether you’re building the next generation of software or exploring AI’s capabilities, remember that prompt engineering is the key to unlocking the true potential of LLMs.